ZIP

zip
اسفند ۱۲, ۱۳۹۵
مزيت استفاده از داده هاي اعتبارسنجي (validation) در فرآيند آموزش توسط كلاسيفاير چيست؟
در حالت عادي دسته بند ها داده ها را به دو دسته داده هاي آموزش و داده هاي تست تقسيم مي كنند كه در آن داده هاي آموزش براي فرآيند يادگيري استفاده مي شوند و از داده هاي تست براي آزمايش دسته بند استفاده مي شود. اما در بعضي اوقات مخصوصا هنگام كار با شبكه هاي عصبي داده ها به سه دسته تقسيم مي شوند يعني در آن داده هاي اعتبار سنجي هم اضافه مي شوند.
اگر فرايند آموزش خيلي طولاني باشد، بيش برازش پيش ميآيد يعني شبكه خيلي به دادههاي آموزش حساس ميشود و اگر دادههاي جديد كمي متفاوت باشند، نتيجهي دقيقي حاصل نميشود. به همين دليل در اين مقاله دادهها يه سه دسته ي آموزش، اعتبارسنجي و آزمايش تقسيم ميشوند.
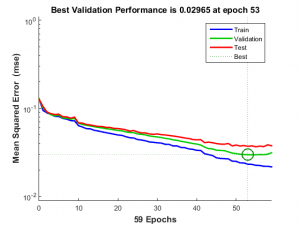
اهميت دادههاي اعتبارسنجي اين است كه از وقوع بيش برازش جلوگيري ميكند.زماني كه فرايند آموزش توسط داده هاي بخش آموزش انجام مي گيرد، توسط داده هاي اعتبارسنجي بررسي مي كنيم كه سيستم خيلي وابسته به داده هاي آموزش نباشد. در شكل يك نمونه فرآيند آموزش و ميزان خطاهاي آموزش، اعتبارسنجي و آزمايش در هر اپوك نشان داده شده است. همانطور كه مشاهده ميشود هر چه تعداد اپوكها بيشتر شود، ميزان خطاي آموزش كاهش مييايد اما به نقطهاي ميرسيم كه كم كم خطاي اعتبارسنجي افزايش مي يايد؛ اين نقطه همان جايي است كه ممكن است از آن به بعد بيش برازش اتفاق بيوفتد به همين دليل فرايند آموزش در آن متوقف ميشود.














دیدگاه ها